4. 로지스틱 회귀
'XX 회귀' 라고 하는 것은, 데이터를 통해 'XX'를 구하는 것이라고 이해할 수 있다. '선형 회귀'에서는 말 그대로 '선'(정확히는 선형방정식)을 찾았다. 로지스틱 회귀에서는 'logistic(기호논리)'을 찾는 것이 목표이다. 그러니까, 어떤 기호값(label)을 분류하는 논리식을 찾는 것이 로지스틱 회귀이다. 논리식이래서 온톨로직한 문장을 찾는건 아니고, 결국에는 선형회귀와 마찬가지로 입력 데이터세트
예를들어 키, 몸무게에 따른 남/여 카테고리 컬럼이 존재하는 경우, 남성과 여성을 구분하는 결정 직선을 구하고자 한다면 로지스틱 회귀를 적용해야 한다.
최소제곱오차에 따른 선형 회귀 방식을 적용하는 경우는 키에 따른 몸무게를 예측하고자 하는 상황과 같이, 이미 존재하는 두 수치 변수간의 관계를 파악하고자 할 때 이다.
위의 사례들에서 알 수 있다시피, 특정 입력 값에 대한 출력값을 예측하는 모델(function)을 구하고자 할 때는 선형회귀를, 레이블이 존재 할 때 입력값들을 구분하고자 하는 기준 function을 구하고자 할 때는 로지스틱 회귀를 적용한다.
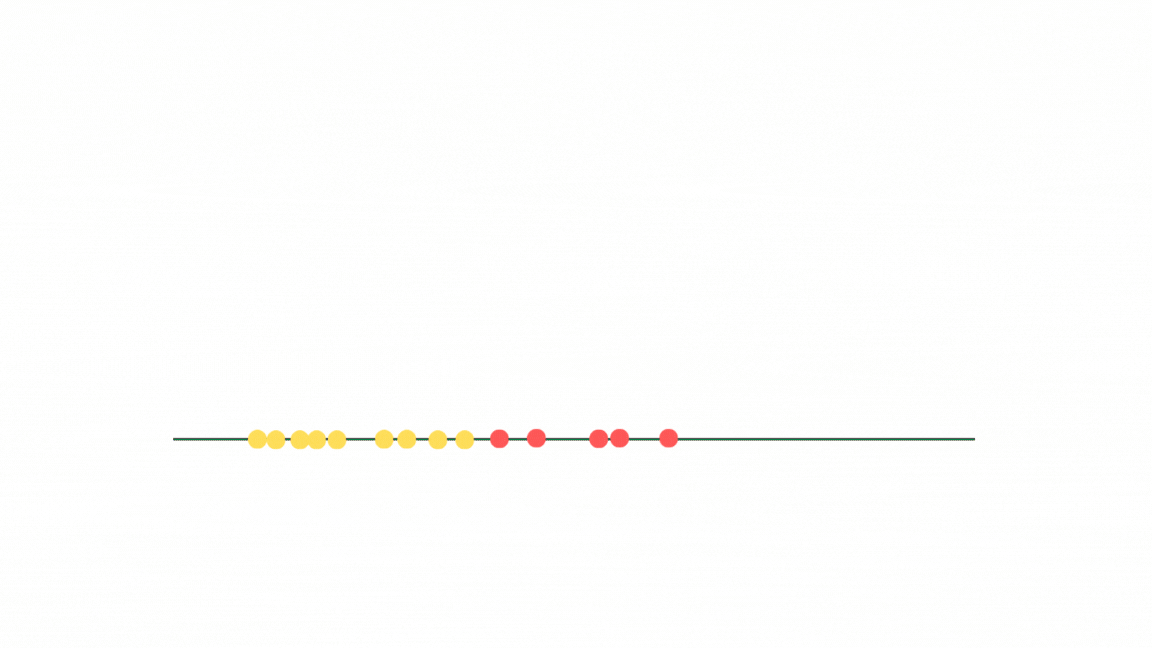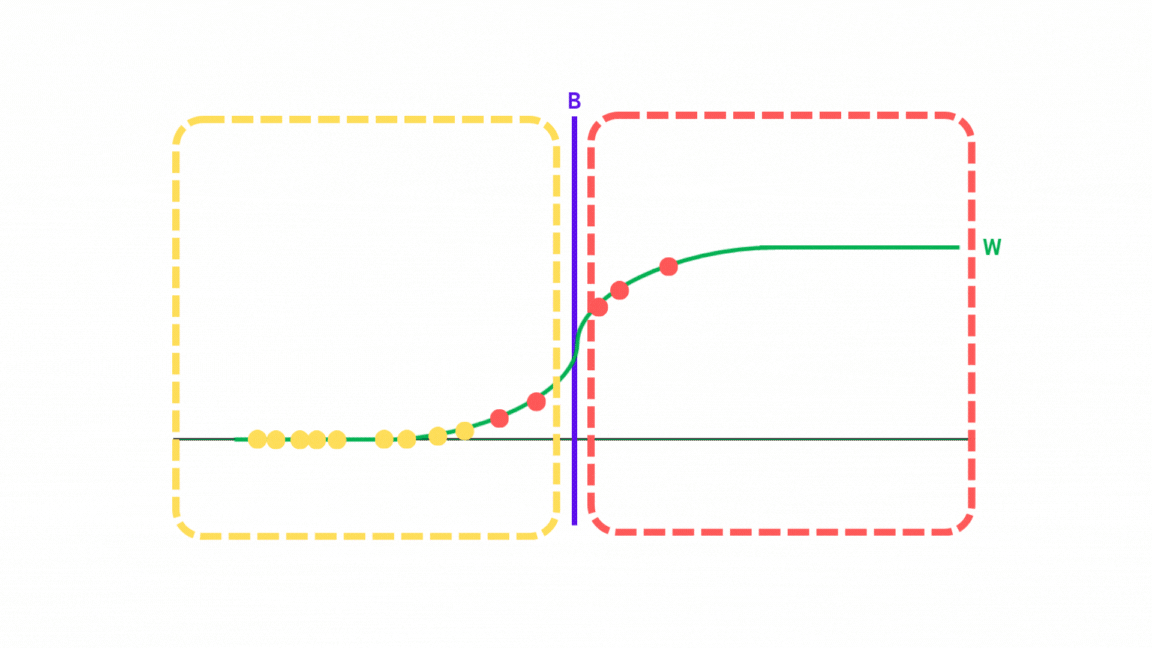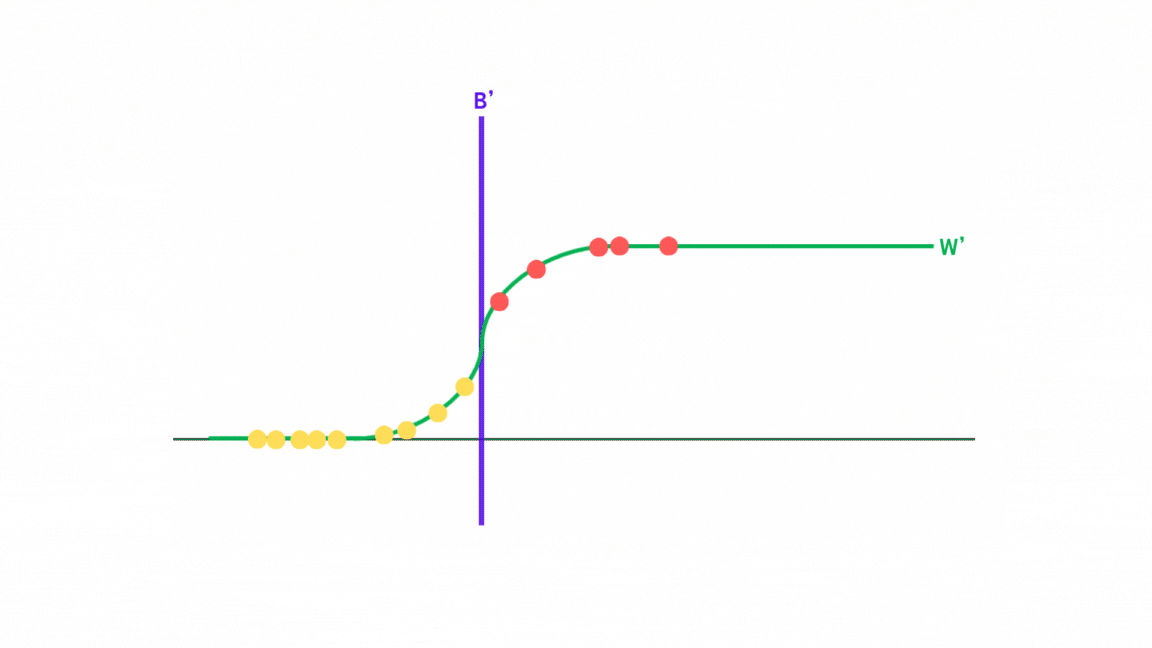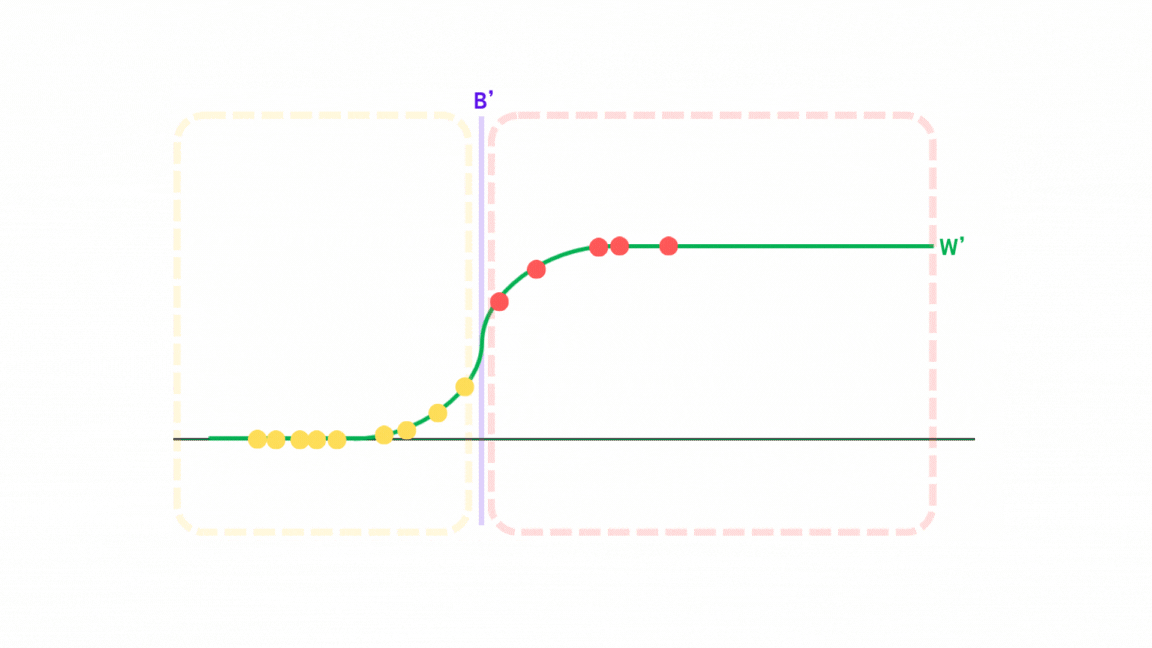
그런데 이제, 선형회귀에서는 결정 공간(치역)이 연속적인 값들로 구성되어 있지만, 로지스틱에서는 결정 공간이 레이블 값(흔히 0, 1)로만 구성되어 있다. 그래서 로지스틱 회귀에서는 시그모이드 함수에 사상된 벡터를 넣어서 0~1사이의 값으로 바꿔버린다.
엄밀히 따지면, 로지스틱 회귀에서
따라서
💡시그모이드 함수와 우도
시그모이드 함수
시그모이드 함수 역시 입력 값을 특정 값으로 사상시키는 함수로, 전체 실수 값을 0~1 사이의 값으로 변환해주는 함수이다.
우도
시그모이드 함수는 입력값에 대해 0~1 사이의 값을 변환한다. 0~1사이의 값은 곧 확률값의 형태로 볼 수 있으나, 어쨌든 변환된 모든 값의 총합이 1이 되리라 보장하지 않으므로 확률밀도함수 모델을 적용해 구할 수는 없고, 대신 이들의 곱을 통해 '그럴싸한 정도'인 우도를 구할 수 있다.
그렇다면 최적의 function은 곧 우도값을 최대로 만드는 함수일 것이다. 쉽게 생각하면, 시그모이드 함수에 로그를 취한 후 미분을 하는 방법이 있겠다. 하지만 이렇게 되면 실제 레이블값이 어찌 되었건 w벡터는 단순히 데이터세트 벡터 세트 X와의 유사성을 최소로 하는 벡터가 될 것이다.
이것이 문제가 되는 경우는 특정 레이블 그룹에서 극단적인 x가 존재하는 상황이다. 온전히 데이터값의 분포로만 W를 구하면 분류가 부정확할 것이다.
따라서, 로지스틱 회귀에서는 우도값이 최대, 즉 '그럴싸 함'이 최대가 되는 W를 구한다. 최대우도
위 식은 학습 데이터가 iid 조건을 충족한다는 전제에서 성립한다. 이렇게 되면, 옳은 레이블이 아니나 시그모이드값이 크게 나오는 경우라도 지수값이 0이 되면서 해당 시그모이드 값이 무시되고 반대의 확률값만 곱해지게 된다.
최대의
여기서 목적함수가 되는 비용함수(cost function)는
💡왜 음수로 바꾸는가
사실 로그 값에 대해 최대가 되는 w를 찾는 것도 동일한 결과를 도출한다. 다만 굳이 음수값으로 바꿔 구하는 이유는 목적함수를 비용함수로 정의했기 때문이다. 비용함수의 goal이 최소지점이므로, 이러한 관점에 맞춰 값을 구하기 위해 굳이 음수로 값을 취해 구하는 것이다. 구태여 비용함수로 정의해 구하는 이유는 최저값 계산이 더 간편하기 때문이라고 한다.
따라서,
로그를 씌워 최종적으로 정리하면 아래와 같다.
비용함수의 형태로 정의하면 다음과 같다. 이제부터는 이 비용함수를
이제
이때,
이것을 이제 데이터 세트 하나씩 곱하여 미분하면 된다. 아마 벡터 연산으로 나타내면 아래와 같은 모양일 것이다. 모든 식에서 0이 나오도록 연립방정식을 풀면 된다.
우행렬의 열벡터 각각은 i번째의 x 벡터이다. 보통은 벡터연산으로
여기서
💡로그의 미분
case1
case2
case3
이제부터는 특정 스칼라 값들에 대한 연산이므로
자연로그가 있으므로, 자연로그 내부의 식은
1.
에 대해 미분하기
2.
에 대해 미분하기
3.
를 에 대해 미분하기
4. 대입하기
5. 미분값이 0이 되는 지점의 w 구하기
인 경우
exponential의 미분은 매우 까다롭다. 그런데, 이런 exponential에 대한 미분을 NxD회 실행해야 하므로, 하나의 CPU를 이용해 순차적으로 미분방정식을 푸는 것은 매우 비효율적이고, 사실상 불가능한 일일 것이다.
따라서, 딥러닝의 학습 시에는 그래픽 연산에 최적화된 프로세서인 GPU를 이용해,
물론, 제아무리 GPU와 같은 하드웨어의 도움을 받아 연산을 효율화 할 수 있다고 하더라도, 기본적으로는 차원 수를 줄인다던가, 데이터 샘플링을 통해 대표성을 갖는 데이터세트에 대해서만 학습을 진행한다던가 하는 방법을 함께 사용한다.