2. 특이값과 특이값 분해
intro
고유값분해는 실수인 고유값과 직교벡터인 고유벡터를 가지도록 정사각행렬을 분해한다. 고유값분해를 했을 때, 모든 행렬이 완벽하게 실수 고유값과 직교인 고유벡터를 갖는 것은 아니다. 즉, 고유벡터는 모든 형태의 행렬에 적용할 수 없다는 한계점을 갖는다.
반면, 특이값 분해는 모든 형태의 행렬에 적용할 수 있다는 장점이 있다.
특이값, 좌특이벡터, 우특이벡터 | 선형대수에서 "특이(singular)"가 갖는 의미는 행렬식이 0인 정사각 행렬을 의미한다. 즉, 정방 행렬이나 역행렬이 존재하지 않는 행렬을 의미한다. 그리고 앞으로 다룰 특이값 분해에서 등장하는 좌특이벡터, 우특이벡터는 각각 원래 행렬 A의 열, 행을 선형독립인 기저벡터로 변환해주는 역할을 한다. 여기서 좌특이벡터는 U 행렬의 열벡터들을 의미하고, 우특이벡터는 V 행렬의 행벡터를 의미한다. 좌특이벡터와 우특이벡터는 직교하는 성질을 갖고 있다.
데이터 사이언스에서 특이값 분해는 다방면에서 활용된다. 그 이유는 특이값분해는 어떠한 행렬이던 간에 행렬을 랭크 1인 조각으로 나눌 수 있으며, 나뉜 조각들이 중요한 순서대로 나온다는 특성을 갖기 때문이다.
조각
특이값분해란?
특이값분해는 행렬을 좌특이벡터(left singular vector)와 우특이벡터(right singular vector), 고유값으로 분해하는 것이다. 좌특이벡터와 우특이벡터는 고유값
고유값 분해와 유사한 지점이 많으나, 특이값 분해는
특이값 분해 공식
기본적으로 특이값 분해는 $$A = U \Sigma V^T$$ 를 구하는 것이다. 이때, A에 A의 전치 행렬을 곱해 대각화 가능한 정방행렬로 만들어준다. 대각화가 가능하다는 것은 곧 분해가 가능한 형태라는 것이다.
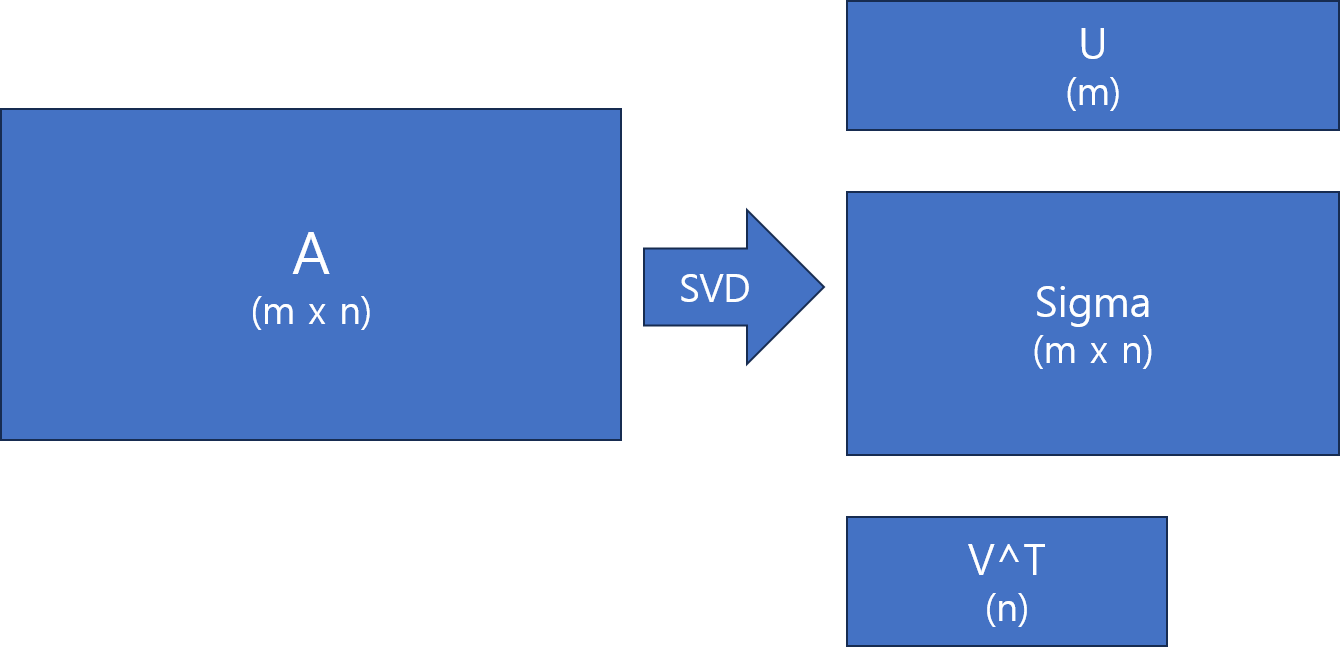
우선
특이값 분해의 조건
는 의 정규직교 고유벡터를 포함한다. 는 의 정규직교 고유벡터를 포함한다. 는 모두의 0이 아닌 고유값이다
특이값 분해는
U는 전치벡터와 직교하며
따라서, 사실상
다음으로는
는 U의 차원수와 동일한 크기를 갖는 고유값의 정방행렬을 가진다. - 반대로
는 와 동일한 크기를 갖는 고유값의 정방행렬을 갖는다.
무어-펜로즈 유사역행렬(Moore-Penrose Pseudo Matrix Inverse)
무어-펜로즈 유사역행렬(:의사역행렬)은 임의 행렬에 A에 대해서 , n > m (데이터개수 > 파라미터)이고 모든 열벡터가 선형 독립일 때 다음의 식이 성립한다. n >m 인 상태는 과결정(overdermined)상태를 의미하기도 한다. 선형회귀분석이 적용되는 아주 일반적인 케이스이다
이때,
반대로 n < m의 경우
A의 의사역행렬을 구한는 방식은 특이값 분해를 거친다.
이때,
선형회귀에서의 의사역행렬 활용
선형회귀라는 것은 기본적으로 독립변수(
선형회귀모형을 수식적으로 재현하면 다음과 같다.
예측의 정확성은 가중치벡터가 관건이라고 할 수 있다. 통상적인 관점에서의 머신러닝은 대체로 이 가중치의 최적값을 최대한 효율적으로 구하는 것이 목표이다.
가중치는 잔차제곱합(Residual Sum of Square : RSS)으로 구할 수 있다. 여기서 잔차라는 것은 예측값과 실제값의 차이, 즉 오차(error :
이 식을 좀 더 대수적관점에 접근해보면
로 볼 수 있다.
대체로 머신러닝에서는 방정식의 수보다 미지수가 훨씬 많기에, 최소자승법을 통해 해결한다. 즉, 잔차벡터의 크기를 최소화하는 가중치벡터를 찾는 것이다.
잔차의 제곱을 취한 벡터인
최소자승법에서
뭔가 익숙한 식이 보이지 않는가? 우항의
따라서, 이 식은
로 나타낼 수 있다. 이렇게 하면 보다 간단하게 선형회귀 방정식을 구할 수 있다. 최적의 잔차를 구할 때까지 가중치 벡터를 갱신할 필요가 없어진다는 것이다.